There are a lot of things you need to know and learn in blogging. You can never be perfect in any field as there are many bigger and better things you will know along the way. Even very small things and files in your website matter a lot in terms of Google rankings and SEO as a whole. One such thing is the “robots.txt” file. Initially, when I started blogging, I did not actually know what this file is and the importance of this file. So, I made a lot of research from various sources and understood its exact use and how important it is in SEO. Many newbie bloggers don’t know what robots.txt is and its use, so I thought of writing a perfect descriptive article on it.
![]()
What is Robots.txt file?
Robots.txt is very small text file present at the root of your site. As most of you know, the web crawlers and spiders are responsible for the development of the entire web network. Ideally, these crawlers can crawl into any page or any URL present on web, even the one’s which are private and should not be accessed.
It does not restrict people from accessing your content.
In order to take control of the files you want the crawlers to access and restrict, you can direct them using the robots.txt file. Robots.txt is not a html file, but the spiders obey what this file states. This file is not something which protects your site directly from external threats, but it just requests the crawler bots not to enter a particular area of your site.
Where do you find robots.txt file?
The location of this file is very important for the crawlers to identify it. So, it must be in the main directory of your website.
http://youdomain.com/robots.txt
This is where the bots and even you can find the file of any website. If the crawlers won’t find the file in the main directory, they simply assume that there is no robots file for the website and there by index all the pages of the site.
Basic Structure of Robots.txt file
The structure of the file is very simple and any one can understand it easily. It majorly consists of 2 components i.e. User agent and Disallow.
Syntax:
User-agent:
Disallow:
Complete Understanding of Exclusion with Examples
Firstly, you should know what the components exactly mean and what their function is. “User-agent” is the term used to determine the search engine crawlers, whether it may be Google, Yahoo or any search engine. “Disallow” is the term used to list the files or directories and exclude them from the crawler listings.
Directory or Folder Exclusion:
The basic exclusion which is used by most of the sites is,
User-agent: *
Disallow: /test/
Here, * indicates all the search engine crawlers. Disallowing /test/ indicated that the folder with name ‘test’ has to be excluded from being crawled.
File Exclusion:
User-agent: *
Disallow: /test.html
This indicates that all the search engine crawlers should not crawl the file named ‘test.html’.
Exclusion of entire site:
User-agent: *
Disallow: /
Inclusion of entire site:
User-agent: *
Disallow:
OR
User-agent: *
Allow: /
Exclusion of Single crawler:
User-agent: googlebot
Disallow: /test/
Add a Sitemap:
User-agent: *
Disallow: /test/
Sitemap: http://www.yourdomain.com/sitemap.xml

How to Create robots.txt file?
Creating a robots.txt file is very simple as there is no special language or technical complication here. You can do this in two ways, one is manual creation and the other is to create the file using tools.
Manual creation of the file is discussed in the above part, so let us go to the usage of tools, which is even simpler. You can use robots.txt file generator tools by SEOBook, Mcanerin, etc.
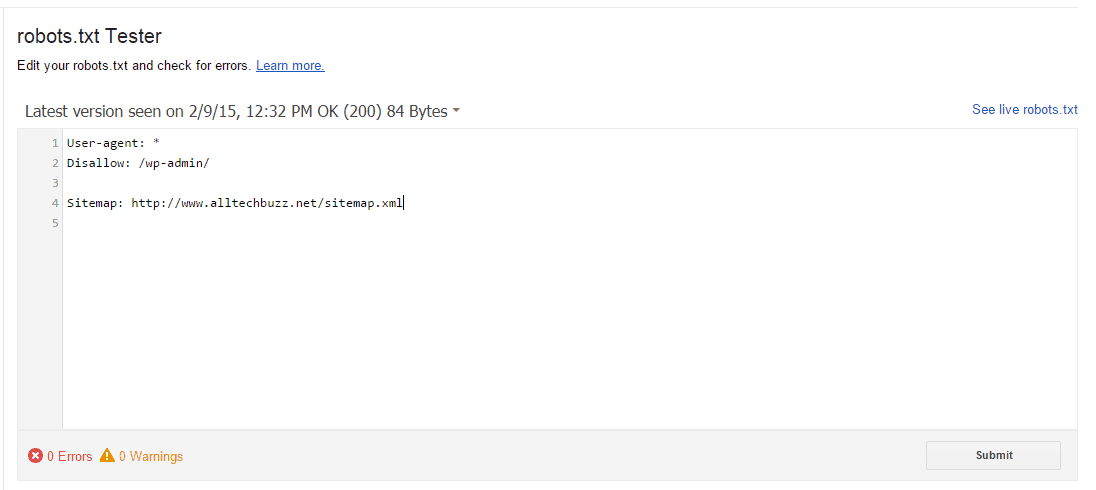
Testing robots.txt file.
The file you created may either work properly or not. In order to test that, you can use the robots.txt tester tool. You can simply submit a URL to the tester tool, The tool operates as Googlebot would to check your robots.txt file and verifies that your URL has been blocked properly.
Here are few steps listed for the webmasters by Google, which will help you test the robots.txt file you created:

Limitations of robots.txt file:
Though the robots.txt is a trust-worthy component when it comes to directing the crawlers, it still has few limitations or disadvantages when dealt practically.
1. The crawlers cannot be forced, they can only be directed: When we use the robots.txt file to disallow a particular path or URL, we are just requesting the web crawlers not to index that particular URL or directory but not forcing the bots to divert. And all the web crawlers might not obey the instructions being given in this file. So in order to block a particular URL, other methods like password protection or usage of meta tags can be implemented which are more effective and efficient.
2. Syntax interpretation might differ for each crawler: The syntax which is mentioned above holds good for maximum percentage of web crawlers. But few crawlers might either not understand the syntax or interpret it in completely different way, which might pull you into trouble.
3. References to your URL’s from other sites cannot be prevented by robots.txt: This is practically one of the main disadvantage of robots.txt file. The file will disallow Google crawlers from accessing any particular URL, when they come in directly into the site. But contrary to this, when that particular URL which you want to block is being referred from some other website, then the crawlers will not stop themselves from getting into the link, thereby listing the blocked URL.
So, in order to prevent these things from happening, you have to go with other protective methods like password protecting files from server or by using the meta tags (noindex, follow) along with the robots.txt file.
Check what Matt Cutts Take on Optimizing robots.txt

Adding Custom Robots.Txt to Blogger
I have already written an article about advanced search engine preferences where I talked about custom robots.txt file, in the Advanced SEO Guide for Blogger. Generally, for blogger the robots.txt file looks something like this:
User-agent: Mediapartners-Google Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://www.alltechbuzz.net/feeds/posts/default?orderby=UPDATED
Steps to Follow:
- Open your blogger dashboard.
- Navigate to Settings > Search Preferences > Crawlers and indexing > Custom robots.txt > Edit > Yes.
- Paste your robots.txt code in it.
- Click Save Changes button.
How to Optimize Robots.txt for Wordpress:
For Wordpress we do have many plugins for doing the same. I would recommend you to go ahead with Yoast Plugin to manage search preferences. Do check out our article on Yoast SEO Settings for complete settings.
The below is an example of robots.txt file that you can use for any domain that is hosted on wordpress:
sitemap: http://www.yourdomain.com/sitemap.xml User-agent: * # disallow all files in these directories Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/ Disallow: /archives/ disallow: /*?* Disallow: *?replytocom Disallow: /wp-* Disallow: /comments/feed/ User-agent: Mediapartners-Google* Allow: / User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: Adsbot-Google Allow: / User-agent: Googlebot-Mobile Allow: /
Once you have optimized your robots.txt file I would highly recommend you to test your file first using the robots.txt tester in Google Webmaster Tools.
So, I hope that helped. Let me know if you have any doubts regarding robots.txt optimization in your comments.
